


In this blog we will look at Kafka adapter, and see how it works. What is Kafka? – It’s a streaming subscriber-publisher system. So, how it’s different from Flume? In essence, Kafka is nothing but a general purpose system where most of the consumer functionality and control relays on your own built consumer programs. While in Flume you have pre-created sources, sinks, and you can also use interceptors for changing data. Therefore, in Kafka you get on the destination exactly what you put on the source. Both Kafka and Flume can work together pretty well, and in this post we will use them both.
Let’s have a look at our existing configuration. Our source is a Oracle database, and we have Oracle Golden Gate for Oracle running for capturing changes for one schema in this database. We have OGG 12.2 in our environment and integrated extract on the source. In the destination we have OGG for BigData installed on a Linux box, and the replication is going directly to trail files on the destination side. The configuration has been made as simple as possible dedicating most attention to the Big Data adapters functionality.
The OGG for Big Data has been installed, and now we need to setup the Kafka adapter. We are copying the configuration files from $OGG_HOME/AdapterExamples/big-data directory.
The kafka.props file needs to be adjusted to define Kafka/Zookeper topics for data and schema changes (TopicName and SchemaTopicName parameters), and the gg.classpath for Kafka and Avro java classes. The rest of the parameters is left default including format for the changes which was defined as “avro_op” in the example.
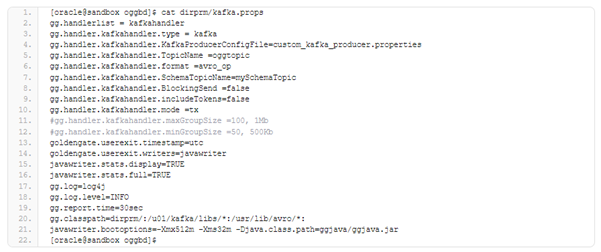
The next file that needs to be corrected is custom_kafka_producer.properties which contains information about our running Kafka server, and some addition parameters like compression is also defined. All the parameters have been left unchanged except “bootstrap.servers” where the information about Kafka service is put.
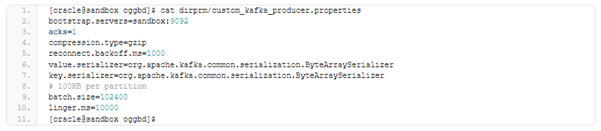
If an initial load is planned through Kafka, we can use something like that parameter file which has been prepared for a passive replicat:
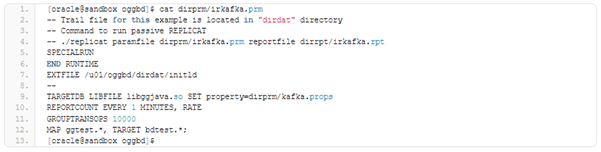
Before starting any replicat, the system needs to be prepared to receive the data. Since the Kafka itself is pure streaming system, it cannot pass files to HDFS without taking help of other program or connector. In the first case, we will have Kafka passing data to Flume. and from Flume will use ‘Flume sink’ to HDFS. You also need to know that you need a Zookeeper to manage topics for Kafka. Assume that we have zookeeper ready, and it is up and running on port 2181.
Kafka version 0.9.0.1 has been used, it has been downloading from https://kafka.apache.org/downloads.html. After downloading, it has been unpacked, and after slight configuration correction it has been started it in standalone mode.
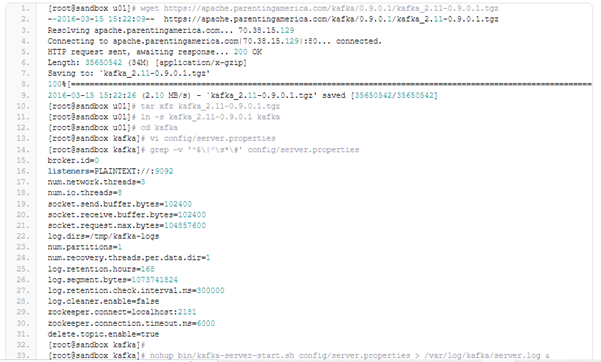
Now we must prepare our two topics for the data received from the GoldenGate. We have defined topic “oggdata” for our data flow using parameter gg.handler.kafkahandler.TopicName in our kafka.props file, and topic “mySchemaTopic” for schema changes. Now, we will create the topic using Kafka’s supplemented scripts:

When the GoldenGate replicat is started all the necessary topics will also be created automatically. You will have to create the topics explicitly only if you want to use some custom parameters for it. There is also an option to change the topic later on when setting up configuration parameters.
Given below is list of the topics we have when one of them has been created manually, and the second one is created automatically through the replicat process.
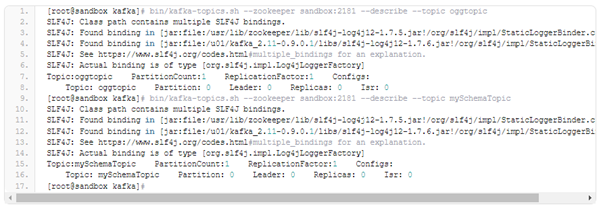
In our configuration we have just a single server, and we have the simplest configuration for Kafka. In a real business case, the configuration can be way too complex. Our replicat will post the data changes to oggtopic, while all the changes and definitions for schema will go to the mySchemaTopic. It has been already mentioned that we will use Flume functionality to write to HDFS. We have prepared Flume with two sources and sinks which will be used to write data changes to the /user/oracle/ggflume HDFS directory. Here is the configuration for Flume:

As it can be seen, we have separate sources for each of our Kafka topics, and we also have two sinks pointing towards the same HDFS location. The data will be written down in Avro format. All preparations have been completed, and we are running Kafka server, two topics, and our Flume is ready to write data to HDFS. However, our HDFS directory is still empty.
Now we will run the passive replicat with our initial data load trail file:
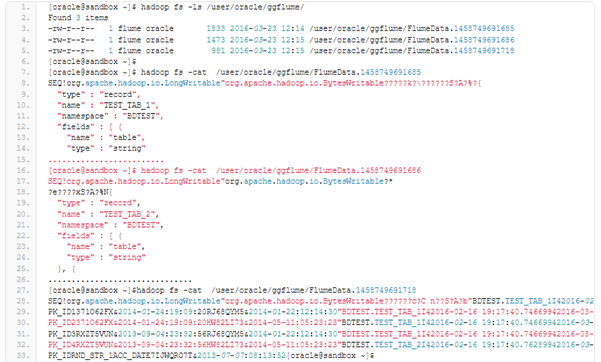
Now let’s look at the results. We have 3 files on HDFS, the first two files describe structure for the TEST_TAB_1 and TEST_TAB_2, and the third file has the data changes, or we can say initial data for those tables. It can also be seen that the schema definition was put on separate files while the data changes were put to the one file.
Now the ongoing replication needs to be created. Our extract is up and running, and passing changes to the replicat side to the directory ./dirdat
Parameter file for the Kafka replicat has been prepared:

We only need to add and start our rkafka replica for the Big Data GoldenGate.
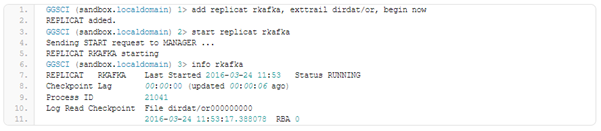
We don’t have dirdat/or000000000 file in our dirdat directory. So, our replicat needs to be slightly corrected in order to work with proper trail files. The sequence for the replicat file is being altered to reflect actual sequence number for the last trail file.

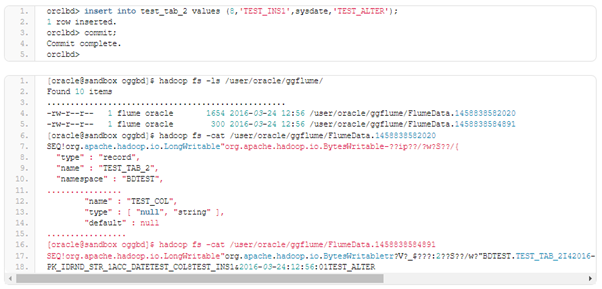
Now, we change some data:
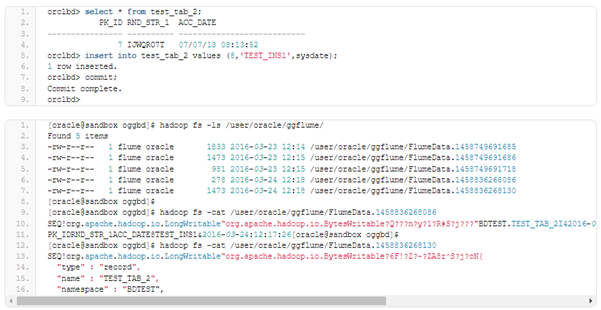
We have our schema definition file and a file with some data changes.
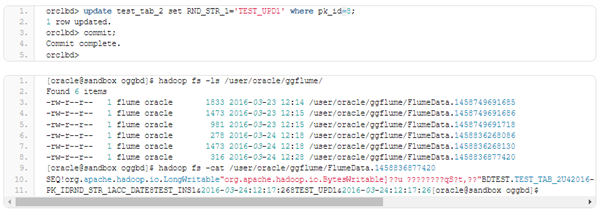
We only have a file with data changes as no DDL changes were made. The transactions must be grouped to the files as per our Flume parameters.
The old value for the updated record and the new one can also be seen. Using that information the changes can be reconstructed, but certain logic needs to be applied to decrypt the changes.
For doing deletion we are getting operation flag “F” and also the values for the deleted record. There is no schema definition file because no changes were made.
Now try some DDL.
No new files on HDFS.
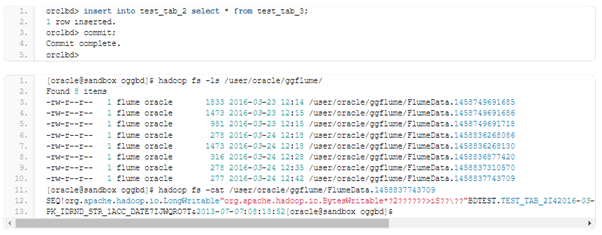
Again, we have only file with data changes. The file we were getting for the previous insert was compared with the insert after truncate, but any difference couldn’t be fined except for the binary part of the avro file. It may require additional investigation and clarification. In the current state it appears it is easy to miss a truncate command for a table on the destination side. We will change the table, and will add a column there.
We are not getting any new files having new table definitions till we do any DML on the table. Both the files (with the new schema definition and data changes) will appear after we insert, delete or update any rows there.
So, are you ready to experience our consulting services for Kafka?
We are here to help, schedule a free assessment today.






