
For implementation of Apache Kafka and streaming data, we should
Simplify architecture by having fewer clusters
Kafka adoption generally results in different Kafka clusters organically occurring in different sections of the organization. The increase in number of clusters may be because of the need of keeping activity local to data centres or for physically segregating data owing to security reasons. With lower number of Kafka clusters, there are lesser integration points for data users, lesser number of things for operation and lowered cost of integrating new applications.
A single company wide data format for events
Apache Kafka supports multiple formats like XML, Avro or Json. But from the company perspective, you should have an enterprise-wide single data format. Integration becomes simpler by having data sets follow the same conventions and being similar in format alongwith streaming data in Kafka. If individual sections of the enterprise use their own format, the processes which uses multiple data streams would be required to process and understand each of the data which becomes a burdening task. With a single data format, each system is required to write X adaptors, one adaptor for each data format it is ingesting. You need to make sure that all integrations and tools use the same data format to simplify the data flow within the organization.
- Data adaption
Different databases like relational databases, Hadoop and others have different data models. Creating a data pipeline between systems will not simplify things if each systems produced data and consumed it in different formats. The end result is that a different format plug-in is required for all source systems. With enterprise-wide single data format, the systems just need to adapt to the common format thereby reducing the format conversions and improving data adaption within the organisation
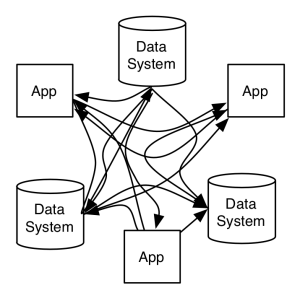
Have a single platform for streaming
If we centralize the platform for data exchange, we simplify the data flow. The shift in connecting all the systems has been shown in the below diagram
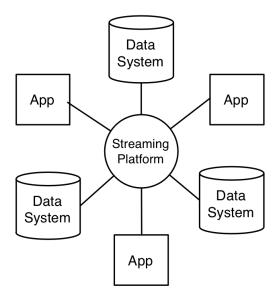
With a centralised event streaming platform
Starting fresh- Start with Avro as your data format
If you have just started with Kafka, Avro is the favored data format that you should choose. It has been found to be the most successful data format for streaming. Its data structures are rich. It is a binary data format that is compact and fast and carries a container file for storing persistent data. It integrates easily with other dynamic languages. It easily defines the schema for your data.
4. Have well -defined parameters for choosing your client
Kafka has clients for different languages. You need to have a well-defined parameter for choosing the clients because it directly affects the performance and the accuracy of applications used by Kafka.
Structure messages as events not as commands
Kafka streams are publish/subscribe naturally. Structure the messages as events and not as commands.
Connect applications and systems using Kafka connect
Kafka Connect provides a simple plug-in REST API for reading source systems and writing them to destination systems. Use Kafka connect to integrate pre-existing applications and systems by using a reusable connector for the specific systems. With built-in scalability advantage of the connectors, you can connect easily with systems having large scale like Cassandra and Hadoop. The connectors are fault tolerant ensuring data flow is consistent and uninterrupted. It allows you to capture all metadata about your data format
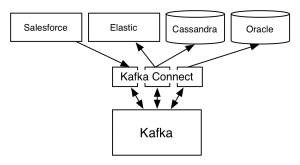
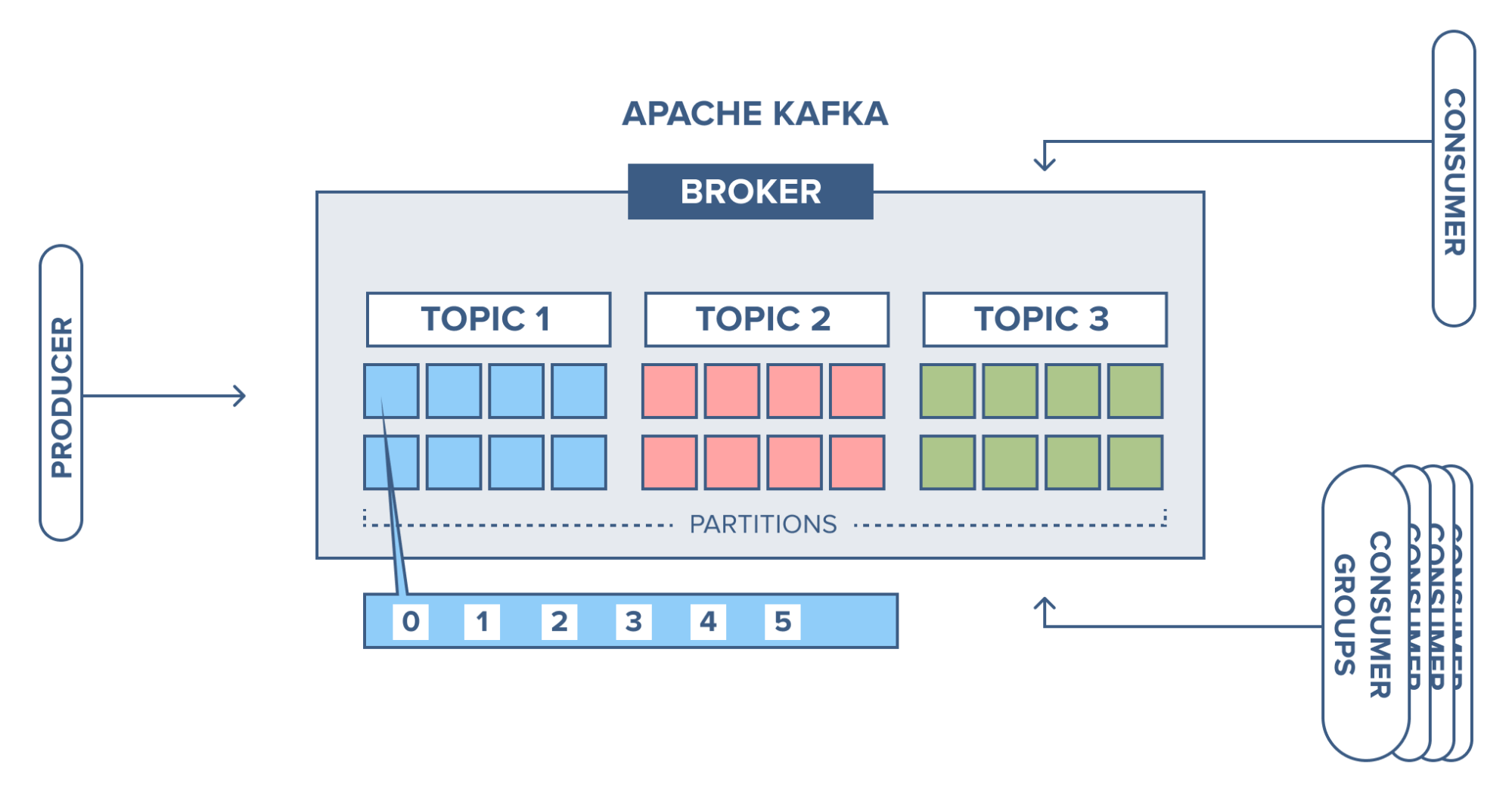
Leverage the stream processing capabilities of Kafka
The stream APIs of Kafka is a library with high stream processing capabilities. Applications working on this library can transform data streams which are automatically made fault tolerant and are distributed over the instances of the applications elastically.
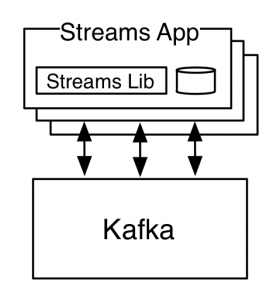
The stream app looks like